
| By Margaret Waligora, Product Manager; Lindsey Gervais, Digital Learning Manager; Wendy Kurtz, Digital Humanities Specialist; Marc Cormier, Director, Digital Scholarship |
Since fall 2018, a growing number of institutions around the world have subscribed to the Gale Digital Scholar Lab, giving libraries, students, and faculty access to their Gale Primary Sources collections in an analysis platform that amplifies the research value of these collections while making text mining approachable for users across the academic spectrum. We listened for clues as to what our users wanted next: Is it a new open-source tool? A virtual teaching assistant that can grade the analysis outcomes from the Lab? An app that lets you build content sets while barbecuing?
One constant request shone through all of the wish-list items from faculty and librarians alike: to be able to analyze their own optical character recognition (OCR) within the Gale Digital Scholar Lab alongside their Gale Primary Sources collections. We’re pleased to announce the initial product feature to support that request! This feature beta release in the Gale Digital Scholar Lab allows users to upload plain-text files; manually create text documents; apply metadata; and clean, build, and manage their content sets in a single environment. Users will be able to analyze and visualize plain-text files they’ve collected alongside their Gale Primary Sources archives to enrich research outcomes and extend the content reach for text mining and analysis.
Here are some steps you can take to ensure your uploaded documents are ready for analysis:
- Upload File or Create a Document within the Platform: You can select multiple files for upload simultaneously and can upload plain-text files (.txt) totaling 10 MB at a time. There are no storage limitations on the upload feature while it is in its beta iteration. A list displaying the file names will appear once the files have been successfully uploaded.
- Apply Metadata: Metadata is key to making rich, flexible visualizations. Without it, only the document text can be analyzed, missing out on valuable connections that can be made about the types of documents in your content sets. There are a couple of ways you can add metadata to your documents: via a quick form that allows you to apply the same metadata to all selected documents or bulk metadata upload.
- Manage Uploaded Documents: Once you’ve uploaded documents, you can review, add and remove, and apply metadata to your documents to ensure it’s ready to be added to a content set for analysis.
- Create New Content Sets: You can create content sets with your uploaded documents, with your Gale Primary Sources holdings, or with a combination of both.
- Review the Newly Created Content Set: Once you’ve created your content set, you can review your uploaded documents alongside the Gale Primary Sources document. You can refine your content set by editing your uploaded text files and removing documents as needed.
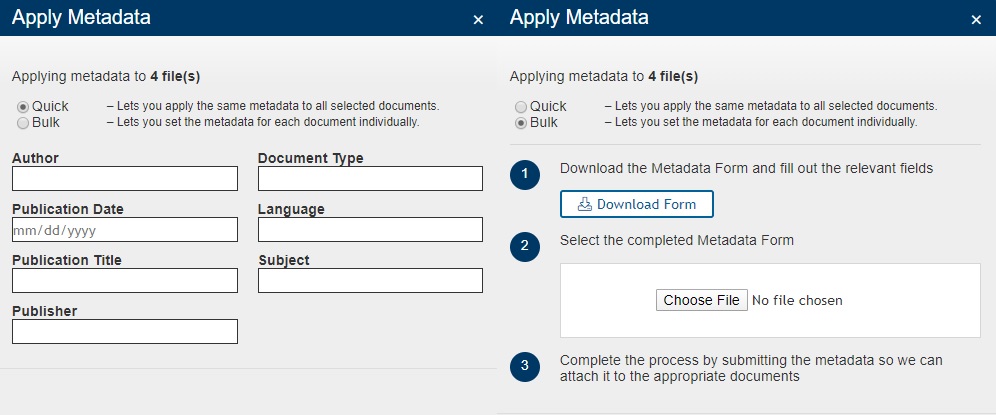
A screenshot of the pop-up window containing the quick and bulk options to apply metadata. 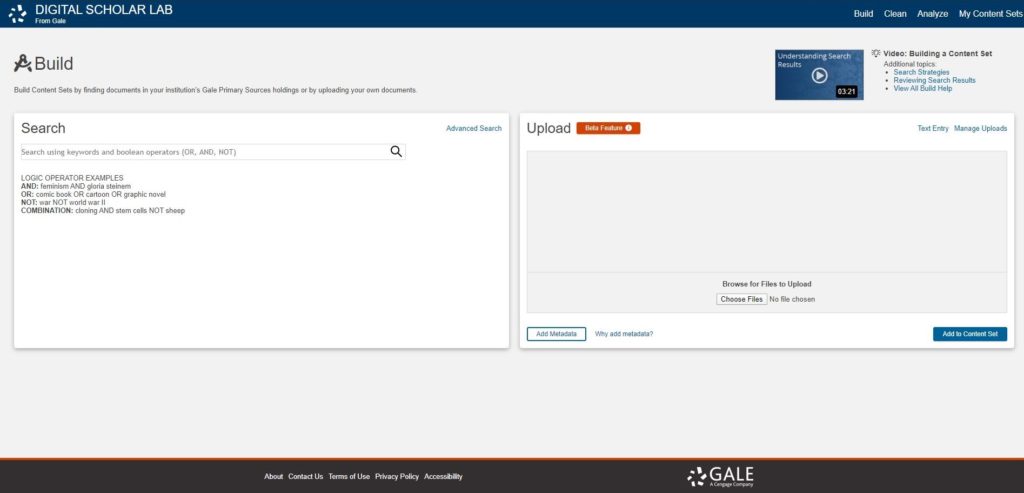
A screenshot of the Build page within the Lab. 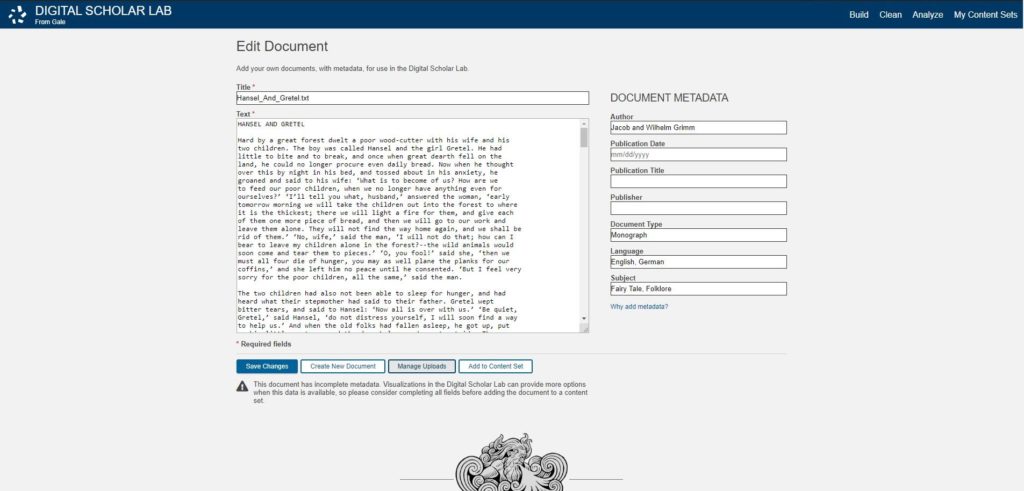
A screenshot of the edit document page in the Lab. 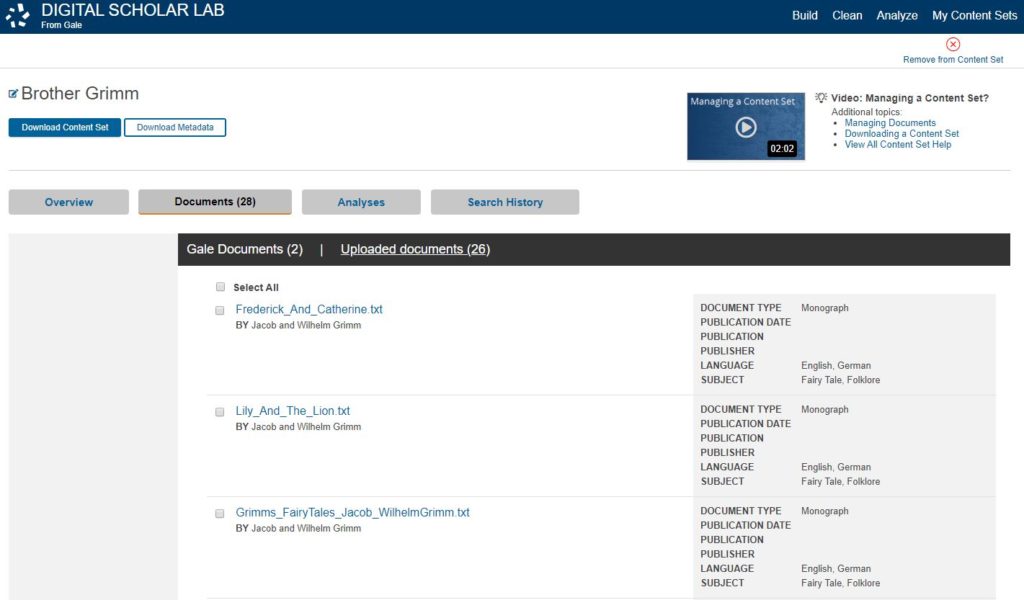
A screenshot of the Manage Content Set page with the uploaded document tab displayed. 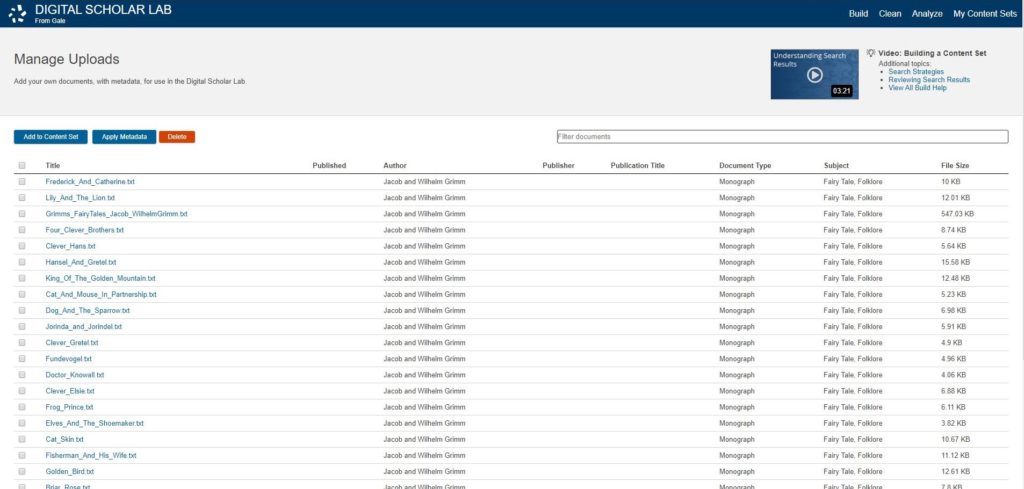
A screenshot of the Manage Upload page within the Lab.
Through this beta feature, we enable researchers with a single space where they can build datasets using rights cleared, open source, or proprietary documents for the purpose of text analysis and visualization. We expand the potential of the Lab by aligning user research and instructional goals with the ability to incorporate outside documents. By responding to our users’ requests, we’ve increased the depth and breadth of content available for analysis, allowing users to discover even more pathways for future research.
The feature is in beta, meaning we’re still tinkering with the implementation. We are actively seeking feedback from users regarding their experience with this feature. If interested in providing feedback, please contact us via [email protected].
FOOTWEAR