
| By Dr. Sarah Ketchley, Senior Digital Humanities Specialist |

This November, I was fortunate to join the team of Dr. Donald P. Ryan’s Pacific Lutheran University Valley of the Kings project on the West Bank in Luxor, Egypt, whose focus during the 2022 dig season was tomb clearance and accessibility work. My visit coincided with the centenary of the discovery of Tutankhamun’s tomb on November 4, 1922, and there were multiple events planned to celebrate the occasion. This blog post will highlight resources and activities related to the centenary, before taking a closer look at news reporting from 100 years ago in The Times of London, which had negotiated exclusive reporting rights with Lord Carnarvon to document the day-to-day discoveries in Tut’s tomb. Gale provides access to The Times Digital Archive in its entirety and is a rich resource for learning about the discoveries of the day. I’ll also use Gale Digital Scholar Lab (the Lab) to investigate some of the trends and topics that made headlines 100 years ago.
Tutankhamun 2022
The American Research Center in Egypt (ARCE) has worked with several scholars over the past year who have lectured on the topic of King Tut to ARCE members and the public. The full playlist is available here on YouTube, including my kickoff lecture in the series.

ARCE has also partnered with Egypt’s Ministry of Tourism and Antiquities (MOA) to offer a diverse selection of Tut-related events and activities. Of note is the restoration of Howard Carter’s Dig House—ongoing work aims to recreate the look and feel of the house as it was in Carter’s day, while providing rich contextual and educational material. On-site is a replica of King Tut’s tomb for visitors to explore, which offers an authentic experience while mitigating the potential for degradation and damage to the tomb itself in the Valley of the Kings.
November 4 also drew an international group of scholars to Luxor for the “Transcending Eternity: The Centennial Tutankhamun Conference,” with Zahi Hawass as its keynote speaker on Friday night.

Speakers during the three-day event discussed various aspects of Tutankhamun’s life and death, along with the history of the excavation and preservation of the tomb and its contents.
Another excellent interactive resource for those interested in the tomb of King Tut within its broader context in the Valley of the Kings is ARCE’s The Theban Mapping Project. This long-standing website recently underwent an overhaul to bring it up to date, and now provides detailed plans of tombs in the Theban necropolis, including royal and other major tombs, along with written overviews and bibliographies. There are also topographic maps of the Valley of the Kings and the West Valley.
The Griffith Institute in Oxford, United Kingdom, houses Howard Carter’s original excavation archive, including letters, diaries, plans, and drawings—much of which is now available online via their website. There is also a centenary exhibit in Oxford, Tutankhamun: Excavating the Archive,that showcases a selection of this material.
Gaining Insights through Contemporary Newspaper Reporting

My previous two blog posts on the topic of King Tut have focused on an MLIS graduate capstone project related to The Times of London news reporting, and the pedagogy of blending digital humanities with the study of the history in an undergraduate classroom. This post will take a closer look at the primary source material underlying the research and teaching, using text analysis tools in the Lab to identify predominant themes and significant figures.
The content set (or dataset) of optical character recognition (OCR) documents for this project amounted to 124 newspaper texts, primarily feature articles, brief notes, and some letters to the editor. The unifying factor is the focus on the discovery of King Tut’s tomb and the global interest in learning about the young pharaoh and his remarkable burial goods.
The project team examined the OCR text exported after building the content set in the Lab and determined that the most effective way to generate meaningful analysis results and to prepare the text output for online publication would be to check each document individually and intervene with manual correction as necessary. This process was facilitated by a group of enthusiastic volunteers who proofread and edited the entire group of articles. While 124 may seem a lot of material, many of the pieces are short, and some of our volunteers were powerhouse editors.
The text from the newspapers was bulk-imported into our project website, where we provide both an image and a text view of each article, along with full metadata.
Analyzing
Having cleaned up each of the files, the next step was to reimport all the texts into the Lab in the Build area of the platform. I was able to bulk-upload all 124 documents at once, which streamlined the process; then I went to Manage My Uploads and selected all 124 to add metadata to the entire selection. Authorship and dates were the two fields I couldn’t complete in bulk, but I applied consistent metadata to the remainder of the fields.
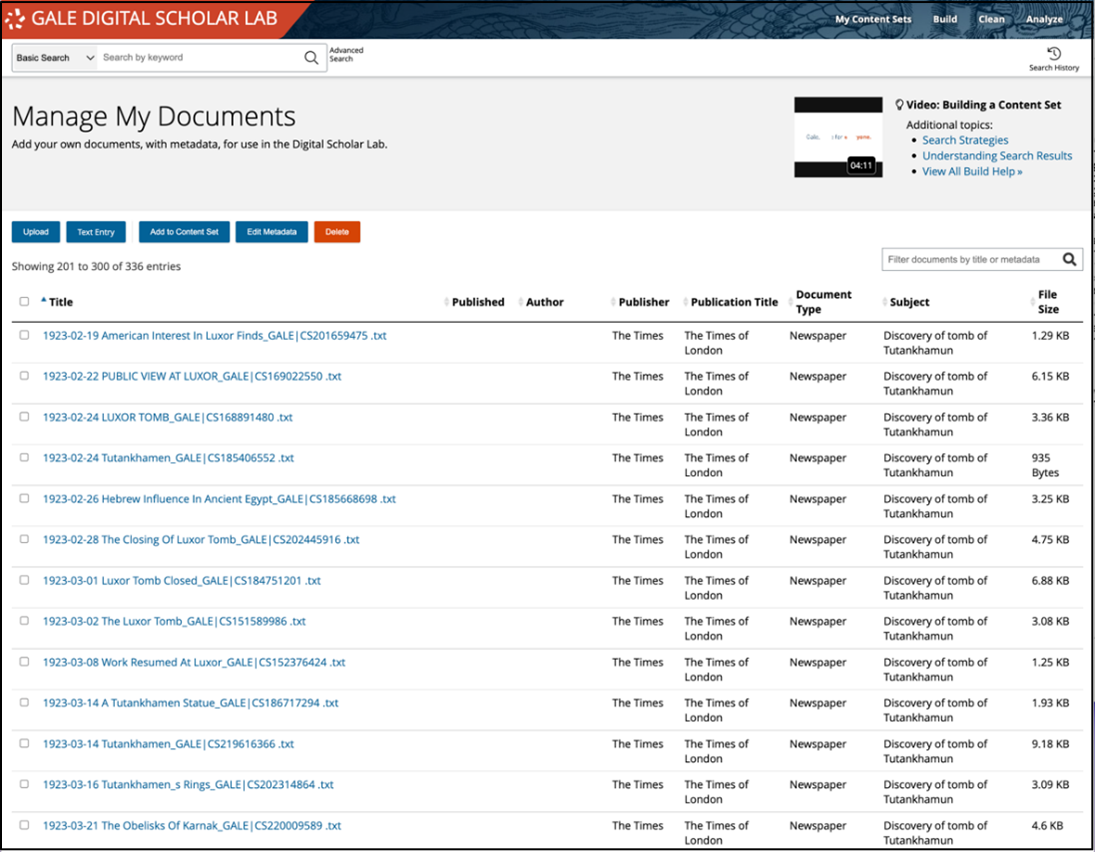
I then selected all 124 documents again and added them to a new content set. I was particularly interested to find out if topic modeling could identify different reporting themes in 1922, 1923, and 1924 and, to a lesser degree, in 1925, since there are fewer documents. Cleaning was relatively straightforward since much of the manual transcription work had been completed outside of the Lab. I used a default clean to remove stop words; normalize white space, line breaks, and other formatting issues; and then also added comma removal to the mix.
I worked through each of the 20 topics I’d specified when I was setting up the tool configuration, and decided what to call each topic based on my interpretation of the connections the algorithm had made. This is a preliminary list of my decisions, which I’ll refine as I look at each of the documents individually.
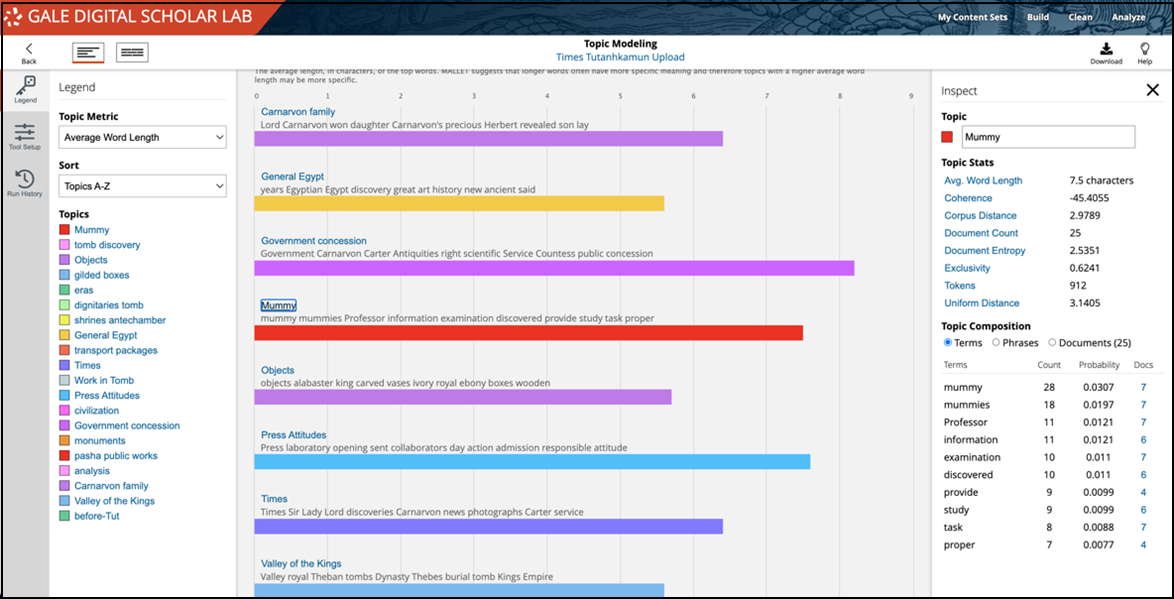
The next step in my investigation was to choose one of these topics and then to dig into the data to see if I could discern patterns or differences on a year-by-year basis between 1922 and 1925. There are two ways to do this type of analysis in the Lab. The first is to look at the Topic Proportion by Document view in the Topic Modeling tool.
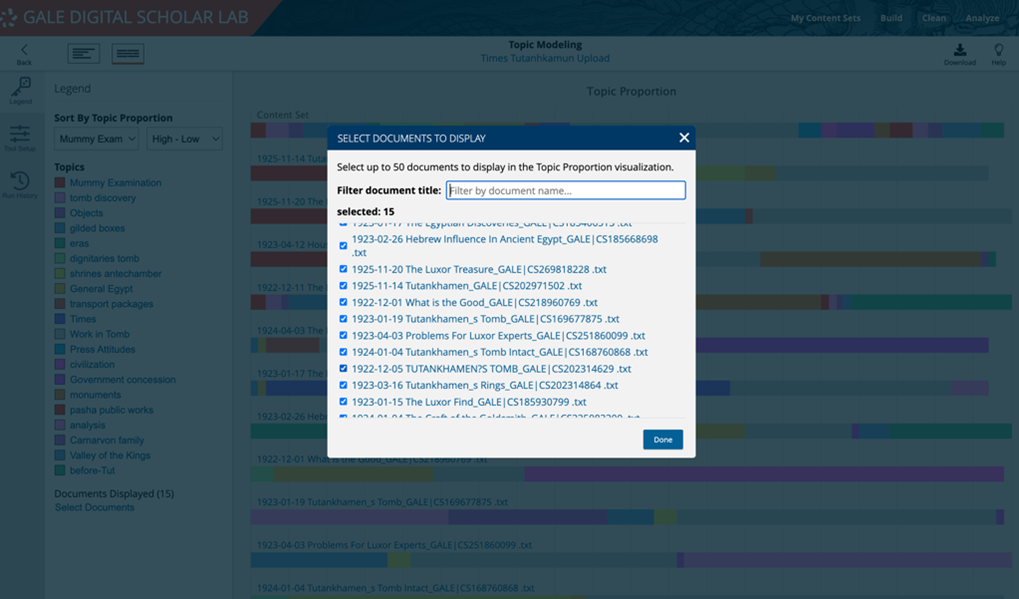
It’s possible to choose up to 50 documents, so selecting documents from a single year based on the file name will generate targeted results.

This image above shows the documents from 1922, and I can see that two contain significant information related to my topic about mummies. The first was written by Professor G. Elliot Smith (article image above), who eventually worked on King Tut’s mummy. In this article, Elliot Smith discusses the importance of X-raying the pharaoh should the excavators find him in the burial chamber, contrasting correct procedure with what had happened in 1907, when Theodore Davis had found what he thought was Queen Tiye’s body (Tut’s grandmother), but didn’t get the bones X-rayed for several months, when it became apparent that the burial was that of a young male.
The results can be regenerated for each of the years, and the image of the topic model downloaded to a local machine. The drawback of this methodology is that the segmented data isn’t saved when a user navigates away from this page. The best way to ensure long-term persistence of this information is to create a new content set from the documents included in a relevant topic, then to run topic models on each collection of material. The Lab helps you keep research well organized with a folder system within the My Content Sets area.
Ongoing Project
The work to gather and analyze related newspaper reporting from 1922 and the years has the potential to offer interesting insights into The Times of London’s exclusive deal. It will also be potentially fruitful to compare this corpus of data with 2022 news reporting.
To learn more about Gale Digital Scholar Lab or Gale Primary Sources, visit gale.com/academic.