
By: Dr. Dallas Liddle, Associate Professor and Chair of English, Augsburg College
Marshall McLuhan is supposed to have said that “the content of a new medium is always an old medium.” He intended the observation as wry cultural criticism, but as a literary historian I am grateful every day that so many new research media are now brimming with the contents of great past media: newsstands, theatres, libraries, music halls, stereopticons, and magic lantern shows. Lately I have started to hope that the benefits of these research tools may go far beyond the convenience of having so many original texts, images, and artifacts instantly available. New methods of “data-mining” using database archives, if we do them creatively and well, may help researchers better understand how the old media forms themselves worked and developed.
The hope grows from recent experience. I started “data mining” the Gale Times Digital Archive not long ago, after struggling for nearly twenty years with questions about Victorian newspapers that traditional archival research had been unable to answer.
My first job out of college was as a reporter on a great little Kansas daily paper, and when I went to graduate school in Victorian literature I thought a good way to learn about the Victorians would be to read their newspapers. I checked a hardbound volume of the London Times for January 1868 out of the University of Iowa Library, walking home a mile with the enormous thing under my arm (imagine a broadsheet-sized hardback), and spent the next month reading The Times at breakfast instead of the Iowa City Press-Citizen. It was a wonderful experience—I followed a thrilling missing-persons case from start to finish—and did help me understand the Victorians better.
It also left me with big questions, because The Times was nothing like the newspapers I grew up with, the one I had worked for, the British papers I had seen while studying abroad, or even the American papers of the same era. Its news genres were unfamiliar—there were no “inverted pyramid” stories, and news was sometimes presented as near-verbatim transcripts of what participants in an event had said. This paper seemed based on completely different principles than the ones I thought all journalism had to follow. It was also huge fun to read. How did its discourse work? How had this form developed? I studied standard newspaper histories, but my what-is-going-on-here questions were not the ones those books seemed written to answer.
I found this frustrating, but only for a little while. I was an academic-in-training looking for things to research, and interesting questions no one had answered were golden discoveries. I worked on pieces of the puzzle over years, writing articles about newspaper anonymity, the origins of the editorial article, and even that exciting 1868 missing persons case. Eventually I wrote a book on Victorian journalism in relation to literature.
For all that work I used the methods my excellent teachers and librarians in graduate school had taught me: immersion in the primary print sources and wide reading in secondary ones. My bigger questions about newspapers, however, were not being illuminated by those methods. Someone can become expert in Jane Austen and Charlotte Bronte through sheer immersion in their printed words, because it is possible to read and dwell upon every word they published. Newspapers were reservoirs of text published in un-dwell-upon-able orders of magnitude. I eventually figured out that the first hundred years of The Times alone must contain twice as much text as every novel—good, bad, or awful—ever published in Victorian Britain. How many people could claim to be well-read in Victorian fiction if Charlotte Bronte alone had written 14,000 books? As I absorbed those numbers, thinking that I could deeply understand a Victorian newspaper just by reading it long enough seemed silly.
When my research library acquired the Times Digital Archive my hopes of adding something more substantial to knowledge of Victorian journalism revived. The user interface was designed around word searches and browsing, but as I searched and browsed I thought there might be other ways to use this tool for what Franco Moretti calls “distant reading” of large amounts of text all at once. It is difficult for a human to read, much less count, every word on a newspaper page, but this database could generate downloadable files of any page on demand, and I discovered that the size of the download was a function of the amount of text on the original page. I chose papers at five-year intervals, saved their page images, compared the file sizes, and found I had a rough way to empirically measure a hundred years of the paper’s growth as a form of text storage, something no scholarly source provided.
After many similar experiments I longed to work “under the hood” of the Times Digital Archive–not just to leverage the existing interface, but to ask questions and get answers from the original data. I am grateful that Gale was willing to work with me, and eventually provided information from the records used to create the database. At that point I began to do still more intensive forms of what might be called data mining,
I am still new to what is now being called the “digital humanities,” however, and basic mistakes I made while doing new media work on old media questions may be worth sharing with those thinking about such projects themselves, or assisting someone else in doing them.
For example, below this paragraph is one of the first dismaying results of my attempts at data mining: an image burned into my memory as the Blue Blob of Despair. I had arranged with Gale to have the database of the Times Digital Archive searched for a count of the total number of words and characters recorded in each day’s paper. This, I thought, would be the picture of the nineteenth-century growth of The Times I had wanted for years, in complete and unmatched detail—one data point per day. When the information arrived I opened it in a near-frenzy of anticipation and generated a scatter plot, expecting to see a slim smooth curve of growth. This is what appeared instead:
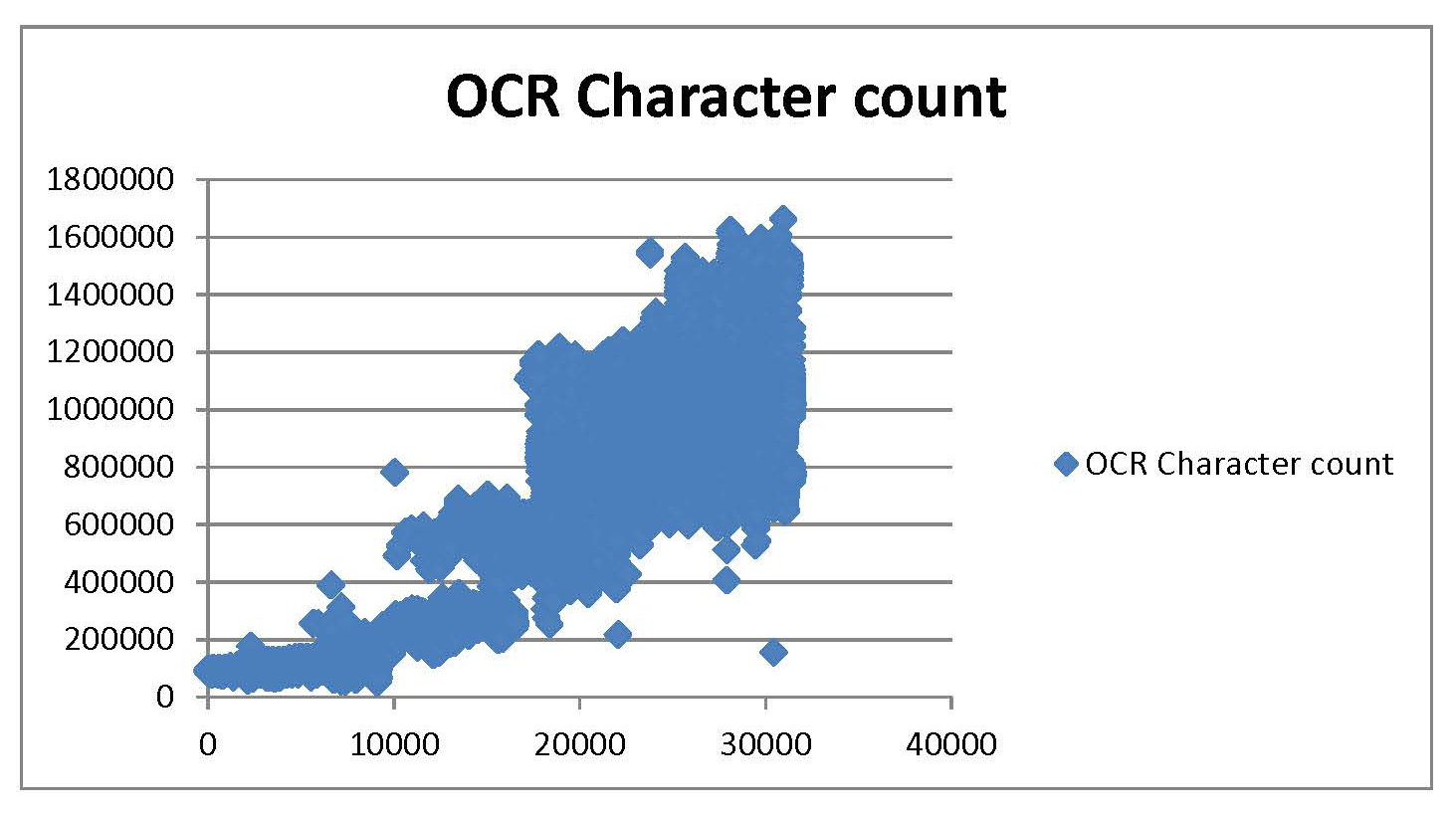
I had believed getting the data would mean getting the answer, and had also believed that I knew exactly what the answer would be. The first message conveyed by this blob of an image was You Were Completely Wrong. The second was You Have a Lot of Work To Do.
Thank goodness the first message was an overstatement—the second was not. Eventually the Gale data did give me good answers. My original ideas about how The Times must have developed in the nineteenth century proved very oversimplified, however—I had been wrong, and needed hard work to put me right. When I have talked since then with young researchers considering dipping their toes into data mining, I have offered three closely related pieces of advice.
1. Let it be ugly, messy, and uncomfortable
In the humanities we usually study finished products of human craft, many or most originally made to communicate with an audience. Their meanings may be dense or difficult, but someone created them to convey a message. Data mining’s information, even about those same products, often takes a different shape, transmitting information to the researcher in ugly forms no one has pre-shaped to our needs. Our reaction can be to defensively simplify and de-uglify right away—to “massage” the data to eliminate outliers, find averages and central tendencies, and concentrate on just the bits that seem clear. I urge new data-miners to keep the data whole and preserve everything it has to say. Speaking of which,
2. Let it tell you what it means.
Researchers and librarians are professional explainers and interpreters, and those of us with hard-won years of expertise can be uncomfortable when looking at a genuine unknown. The urge to immediately explain new data in terms of some known frame or story is remarkably powerful. It was only after I stopped desperately trying to make the Blue Blob’s original data mean only what I had formerly wanted it to mean and lived with its details for a few weeks that its true patterns and structures became clear. So,
3. Plan to figure it out over cycles and processes, not all at once.
Many of us teach iterative thinking to our students, but when our own research questions (and careers) are involved we want to get the answer and publish the paper. I generated and re-generated the Blue Blob at different scales and sizes and sections for weeks before I thought I understood how its three major patterns could have been generated by the developing production history of the newspaper—and it was months later when I figured out there was a significant fourth pattern to understand as well.
With a new medium’s perspective on an old medium’s form, I think I finally have the greater understanding I have long wanted of how the Victorian Times on my Iowa City breakfast table took its shape—and hope soon to publish that new view of its history. The sheer number and availability of the electronic media archives, however, means that there must be many hundreds of similar projects waiting to be done to answer many similar questions. It may take a little ingenuity—perhaps working against or around the way the tool was designed—but data mining of some kind is now within reach of any library user, and interesting, unexpected answers to many of our biggest research questions have probably never been closer.